
“As stakeholders around the globe continue toward establishing laws, regulations, policies, and standards for the rapidly developing field of AI, it’s critical that appropriate terminology is used in connection with the data, content, information, and other training materials powering these generative AI systems.”

Sources: ChatGPT, DALL·E 2 and Elizabeth Rothman
The generative artificial intelligence (AI) revolution the world is currently experiencing is powered by data. But what exactly are “data” and how can we make the term fit for use in the complex landscape of generative AI? In simple terms, data in this context can be any digitally formatted information. However, there is an inconsistency in the usage and understanding of the term when it comes to what is encompassed in a dataset used for training a generative AI model. Often, there is metadata or even identifiable information which, although possibly unintended, ends up being part of the training data. There can also be legal implications linked to the data, including systems trained on copyrighted or licensed works, or, for example, systems trained with any visual or textual information containing personal health information.
The lack of a comprehensive multidisciplinary understanding of what comprises data will continue to generate challenges for lawmakers, developers, and rights holders around the world as these systems continue to develop at a rapid pace. It is crucial to develop a shared vocabulary beyond “data” or “dataset” to describe what are encapsulated in the resources used to train a generative AI model. This is an important step toward setting up the necessary safeguards and understanding the implications of some of these models as we enter this new generative age.
Defining AI
Generative AI is a type of narrow AI that uses machine learning (ML) to train a system on specific inputs with the intent to produce a novel output. However, at times the outputs may bear resemblance to a specific input. This is often, but not always, due to repetition during the training process of a specific model. Generative AI, in its current form, is narrow in the sense that it is trained and programmed to do a specific task and provided with data to accomplish that task, as opposed to a more general artificial intelligence that would be able to think on its own and expand outside of its programmed abilities. Regardless of the narrow scope, these systems are still capable of producing extraordinary content and output.
“The term ‘machine learning’ means an application of artificial intelligence that is characterized by providing systems the ability to automatically learn and improve on the basis of data or experience, without being explicitly programmed.” This definition of ML is from the National Artificial Intelligence Initiative Act of 2020 (DIVISION E, SEC. 5001), codified in 15 U.S.C. § 9401(11). Large language models (LLMs), generative adversarial networks, and diffusion models are a few of the types of ML methods that power many of the text generation tools, such as ChatGPT, and image, audio, and video generation tools, such as Midjourney, Google’s Imagen, or Adobe Firefly. Technology company NVIDIA publishes the Official NVIDIA Glossary which contains a robust set of definitions, descriptions, and explanations for many of the terms used within AI.
In practice, a combination of AI methods can often be used to create an overall AI solution. For example, in the U.S. Department of Health and Human Services (HHS) Trustworthy AI (TAI) Playbook, a Benefits Claims Call Center Bot is highlighted as one use case of an AI system that is powered by multiple ML methods that power an automated messaging system solution.
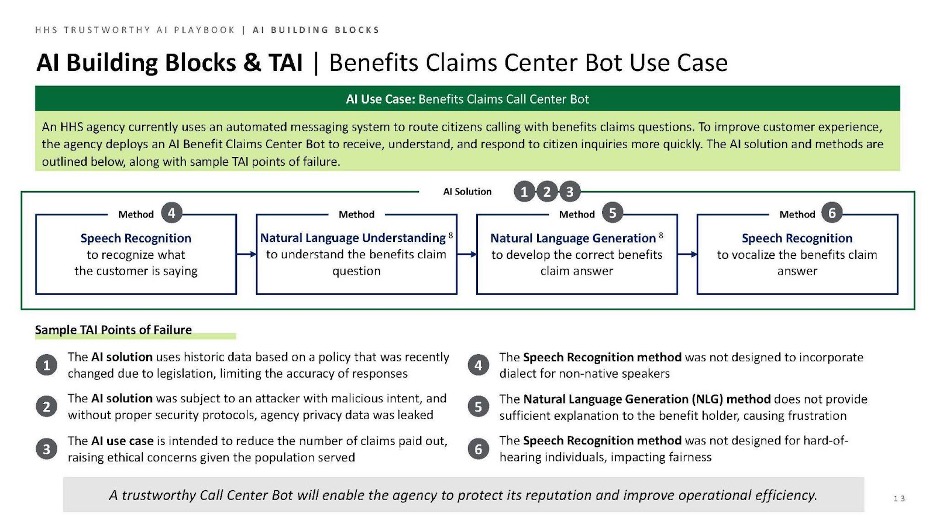 (Source: HHS)
(Source: HHS)
Breaking it down further, the analysis of an individual AI method can be separated into three distinct buckets: (1) input or what later in the article are referred to as “training materials”; (2) the model and tool; and (3) the output.
 (Source: Franklin Graves)
(Source: Franklin Graves)
As stakeholders around the globe continue toward establishing laws, regulations, policies, and standards for the rapidly developing field of AI, it’s critical that appropriate terminology is used in connection with the data, content, information, and other training materials powering these generative AI systems. Such an approach is supported by existing AI transparency frameworks and related proposals for AI model provenance and authenticity.
Terminology Standards: Training Materials
At present, the terms “data,” “training data,” and “datasets” are widely used terminology to categorize the diverse content and information used in connection with developing ML technologies. While “datasets” may be widely recognized as a technical term when used within the context of databases across certain industries, as discussed below, it is important to note that data are simply one type of information that may be gathered and used during the training process of developing a generative AI system. To more accurately reflect the range of materials used in training ML technologies we should adopt the use of the terms “training materials” and “training sets.” These terms offer a more comprehensive view of the different types of data and information used in ML training including text, images, metadata, and other forms of structured and unstructured data.
Training materials can comprise various materials and information, including copyrighted works (licensed or unlicensed), public domain works, facts, and other non-copyrightable information, raw data (structured and unstructured), personal information, personal health information, and metadata. Moreover, the nuances of how such training materials are copied or otherwise accessed during the ML training process can vary depending on the type of ML method. Specifically, it’s important to understand how a model is designed to ingest, analyze, or otherwise generate data from training materials. For example, the U.S. Copyright Office (USCO) released clarifying policy guidance on the registration of works that contain material generated by AI. In its guidance, the USCO notes, emphasis added, “These technologies ‘train’ on vast quantities of preexisting human-authored works and use inferences from that training to generate new content.”
In some instances, data are extracted from the training materials during the learning process and used to improve the model. For example, a digital image file may contain metadata identifying the work’s author, software, tools, or equipment used to create the digital file. A digital image file may also contain associated alt text which is a written description of the image that is often provided for accessibility purposes. All such data are valuable during the machine learning process especially for models designed to provide text-to-image or text-to-video functionality.
It’s also important to understand the practical aspects of how training sets operate. Distributing open-source training materials is often infeasible due to challenges associated with storing and transferring terabytes of training materials. Training materials are sometimes compiled using links to internet storage locations (such as cloud hosting lockers or website servers and content delivery networks) to download or otherwise access copies of training materials. For example, LAION explains that its datasets “are simply indexes to the internet, i.e. lists of URLs to the original images together with the ALT texts found linked to those images.”
Lastly, using the terms “training materials” and “training sets” helps to reduce confusion about how copyright laws are written worldwide, since many of the statutes don’t offer protections for facts, information, or what are typically referred to as “data”. For example, U.S. copyright laws don’t allow for the protection of data, facts, or other information (even if compiled in a database eligible for copyright protection). In the European Union (and under certain circumstances in the United Kingdom) there are sui generous database rights that allow for ownership claims to both a database and the underlying data that are included within. But that’s still just one type of copyrightable work.
Technical Standards: Model Provenance and Output Authenticity
There currently exists an opportunity for AI stakeholders to design, adopt, and implement industry standards that promote provenance and authenticity across the entire lifecycle of AI technologies, from training sets to models and tools to outputs. Central to such provenance and authenticity efforts is transparency. As noted in the National Institute of Science and Technology (“NIST”) AI Risk Management Framework, “Maintaining the provenance of training data and supporting attribution of the AI system’s decisions to subsets of training data can assist with both transparency and accountability.” Building upon this concept, transparency can be applied in two ways within the AI space.
First, it’s necessary to establish clear records as to what training materials or training sets are used to build and deploy models that power AI solutions. Google published The Data Card Playbook as a proposed standard of “structured summaries of essential facts about various aspects of ML datasets needed by stakeholders across a project’s lifecycle for responsible AI development.” Similarly, Microsoft makes available its Aether Data Documentation Template in what it describes as an effort to “promote more deliberate reflection and transparency about how these datasets might affect machine learning models.” Each allows for the expanded documentation of training materials that goes deeper than simply labeling everything as “data.”
 (Source: Google)
(Source: Google)
The European Parliament recently approved a final draft of the EU AI Act, which now proceeds to the EU member states for discussion and further review. Under the final draft, a generative AI tool will have to disclose what, if any, copyrighted materials were used for training. This further solidifies the importance of transparency into what training materials are powering an AI tool. The AI Act has the potential to force transparency practices beyond the EU’s borders, much in the same way the General Data Protection Regulation (GDPR) had global implications for business privacy practices.
Second, AI service providers will need to support transparency through, among other things, proper disclosures to end users regarding the use of AI technologies. This includes when a service provider is providing an AI technology as a standalone product or service, or a service provider is integrating AI technologies within the services or products supplied to end users.
Service provider transparency includes the development of AI technologies that support end users in the proper disclosure of the use of AI in the outputs of such AI technologies. The Content Authenticity Initiative (CAI), announced by Adobe in 2019 in collaboration with The New York Times Company and Twitter, is an example of one currently available standard for digital content attribution. Partnership on AI’s (PAI) Responsible Practices for Synthetic Media offers a framework with “recommendations for different categories of stakeholders with regard to their roles in developing, creating, and distributing synthetic media.” Social media platforms, including LinkedIn and TikTok, are beginning to publish policies that request end-users disclosure AI-generated content. TikTok is reportedly working on a disclosure tool.
Generative AI tools are here to stay and will continue to become even more engrained into the products, services, and experiences we encounter on a daily basis. Improving the terminology is an important step as we move forward.
Author Elizabeth Rothman asked ChatGPT for an image generating prompt based on this article. It returned: “Visualize a landscape where various forms of data – text, images, metadata, and structured and unstructured data – are amalgamating into a powerful stream, symbolizing the training materials feeding into a futuristic, glowing AI model. This AI model, at the center, radiates waves of influence, symbolizing its potential implications and the multidimensional considerations we need to take into account.” The prompt was then fed into DALL·E 2 to generate the cover image for this article.

![[Advertisement]](https://ipwatchdog.com/wp-content/uploads/2024/04/UnitedLex-May-2-2024-sidebar-700x500-1.jpg)
![[Advertisement]](https://ipwatchdog.com/wp-content/uploads/2024/05/Quartz-IP-May-9-2024-sidebar-700x500-1.jpg)
![[Advertisement]](https://ipwatchdog.com/wp-content/uploads/2024/04/Patent-Litigation-Masters-2024-sidebar-700x500-1.jpg)

![[Advertisement]](https://ipwatchdog.com/wp-content/uploads/2021/12/WEBINAR-336-x-280-px.png)
![[Advertisement]](https://ipwatchdog.com/wp-content/uploads/2021/12/2021-Patent-Practice-on-Demand-recorded-Feb-2021-336-x-280.jpg)
![[Advertisement]](https://ipwatchdog.com/wp-content/uploads/2021/12/Ad-4-The-Invent-Patent-System™.png)







Join the Discussion
No comments yet.