
“If companies train their machine learning models without adequate rights to their underlying data, they risk having to jettison the entire model.”
 A widespread concern with many machine learning models is the inability to remove the traces of training data that are legally tainted. That is, after training a machine learning model, it may be determined that some of the underlying data that was used to develop the model may have been wrongfully obtained or processed. The ingested data may include files that an employee took from a former company, thus tainted with misappropriated trade secrets. Or the data may have been lawfully obtained, but without the adequate permissions to process the data. With the constantly and rapidly evolving landscape of data usage restrictions at the international, federal, state, and even municipal levels, companies having troves of lawfully-obtained data may find that the usage of that data in their machine learning models becomes illegal.
A widespread concern with many machine learning models is the inability to remove the traces of training data that are legally tainted. That is, after training a machine learning model, it may be determined that some of the underlying data that was used to develop the model may have been wrongfully obtained or processed. The ingested data may include files that an employee took from a former company, thus tainted with misappropriated trade secrets. Or the data may have been lawfully obtained, but without the adequate permissions to process the data. With the constantly and rapidly evolving landscape of data usage restrictions at the international, federal, state, and even municipal levels, companies having troves of lawfully-obtained data may find that the usage of that data in their machine learning models becomes illegal.
If companies train their machine learning models without adequate rights to their underlying data, they risk having to jettison the entire model. Without adequate planning, companies may find themselves unable to comply with court orders to remove traces of wrongfully-obtained data. This may be true even if only a small portion of the ingested data was problematic. Simply put, most machine learning models lack a “rewind button” to back out the traces of problematic data, particularly those based on neural networks. This vulnerability appears to have been the downfall of at least one target of an Federal Trade Commission (FTC) investigation, Everalbum, discussed below.
This article outlines the problem of having no “rewind button” in typical machine learning models, and suggests solutions, both architectural and behavioral, to minimize the risk that an adverse court order will force companies to delete their models.
The Technical Problem: Neural Networks
Products using Machine Learning (ML) permeate society today. Examples include speech recognition engines like Siri and Alexa, image recognition systems, and product recommendation tools. These systems “think” like a human brain, with the ability to determine whether a new image, or sound, or some other data sufficiently matches a “known” signal. These systems are called “neural networks.”
To develop, or “train,” neural network (“NN”) ML models, engineers collect a data set (training set) to be used to train the neural network algorithms, for example – a set of pictures that contain dogs, and a set of pictures that do not contain dogs. The system then digitizes or prepares the training set so that through an iterative mathematical process, distinguishing common characteristics (“signals”) can be found. A neural network “model” is the output of this iterative process. The model is embedded in a product along with a set of code (“a runtime”) that knows how to use the model.
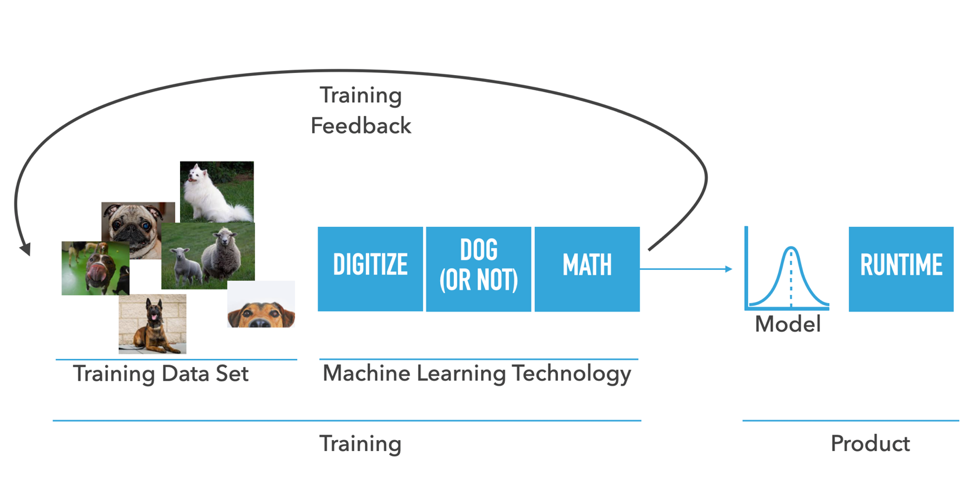
After training, a NN ML system does not retain the images that had been used to train the model, but instead retains values at individual nodes in the neural network model that represent the aggregation of the training data (images). In the example above, there is no database of images of dogs retained in the model, and the system does not match a new image against a known database of dog images – doing so is impossible with neural networks. Rather, these neural network systems, through the use of trained models, “know” if an image is a dog, much in the way that humans “know” if an animal is a dog. This “knowledge” results from training the model over thousands or even millions of examples, in a true/false approach, whether an image is of a dog. In aggregate, these true/false training exercises are used to generate a signal that defines the essential outward appearance of a dog.
In these neural network systems, it is typically impossible to remove traces of the data that were ingested to train the model. With each set of ingested data, the model “learns” from each successive true/false example. Generally, it is impossible to remove the imprint of the training from a previously ingested set of data. Thus, there is no “rewind button” for deleting traces of ill-gotten data.
Legal Trouble: The Everalbum Example
The inability to remove problematic data may have contributed to the demise of Everalbum, a photo storage service that was shut down through litigation with the Federal Trade Commission (FTC), which concluded in 2021. Everalbum solicited users to upload photos to its server, allowing users to generate shareable photo albums.
In 2017, Everalbum launched a “Friends” feature in its app that used facial recognition technology to group users’ photos by the faces of the people who appear in them. Everalbum allegedly enabled its facial recognition service by default for all mobile app users that launched the Friends feature. Between July 2018 and April 2019, Everalbum allegedly represented that it would not apply facial recognition technology to users’ content unless users affirmatively chose to activate the feature. Beginning in May 2018, likely in response to restrictive biometric laws in Illinois, Texas, Washington, and the European Union, Everalbum obtained affirmative consent from residents of those jurisdictions in order to include their data in this facial recognition service. Thus, for residents in those jurisdictions, Everalbum had express consent from its customers to use their images in its neural network ML model for facial recognition, whereas such consent was not express for its other customers.
The FTC required Everalbum to destroy any “Face Embeddings” obtained from users who did not give affirmative consent for facial recognition, and “destroy any Affected Work Product.” [Everalbum final settlement rec memo 3.25.2021]. Thus, Everalbum was required to delete “the models and algorithms it developed by using the photos and videos uploaded by its users.” [May 7, 2021 Press Release]. Ultimately, Everalbum shuttered its services. Quite possibly, Everalbum was unable to delete only the problematic data from its neural network, and thus could not resume with just the subset of data for which it had obtained affirmative consents.
Technology Alternatives: k-Nearest Neighbor (k-NN)
Machine learning models may be trained using approaches other than neural networks. One alternative gaining traction is k-nearest neighbors, or “k-NN” (and note that the “NN” in k-NN does not refer to neural networks). These k-NN systems retain the underlying data that is input into the model, and the engine seeks to determine which data in the model are “closest” to a new input. Computationally, such k-NN systems had been limited in the kinds of data that could be processed. For richer data types (e.g., photos or videos), it may become prohibitive to determine if a new input is “close” to existing data points in the system. However, with technological improvements developed at some technology companies, and for less computation-intensive data types, k-NN is becoming a viable alternative to neural networks. Patient records, home loans, insurance policies, credit and transaction information, etc., may be the kinds of data that can be processed efficiently through k-NN systems. As computing power accelerates, these k-NN systems may be an increasingly viable approach.
One advantage of k-NN systems is that data can be removed from the system if problematic. For example, if a portion of a set of home mortgage records had been wrongfully obtained (e.g., for lack of proper client authorizations, or due to improper bias in selection), that portion of data can be removed from the system altogether. The model for generating new mortgage records may then proceed free from any taint of the prior data that had once been part of the system. Thus, unlike neural networks, these k-NN systems have the feature of a “rewind button” for removing problematic data.
In the context of the Everalbum example, if a k-NN system had been used, the owners presumably could have retained the data from their customers from whom proper consent had been obtained (e.g., those in Texas, Illinois, Washington, and the European Union), and removed the remainder of their customer data, and resumed operations. (how a k-NN could be used in this facial recognition context, of course, is another question). Depending on the technological demands of the system, a k-NN approach may give flexibility in complying with changing legal landscape that neural networks cannot.
In Part II of this two-part series, we will discuss the implications of the absence of a “rewind button” in neural network machine learning systems, and the review scenarios where companies may be required to remove date from their machine learning models (or shut down if unable to do so).
Image Source: Deposit Photos
Author: nils.ackermann.gmail.com
Image ID: 102390038


![[Advertisement]](https://ipwatchdog.com/wp-content/uploads/2024/04/Patent-Litigation-Masters-2024-sidebar-early-bird-ends-Apr-21-last-chance-700x500-1.jpg)

![[Advertisement]](https://ipwatchdog.com/wp-content/uploads/2021/12/WEBINAR-336-x-280-px.png)
![[Advertisement]](https://ipwatchdog.com/wp-content/uploads/2021/12/2021-Patent-Practice-on-Demand-recorded-Feb-2021-336-x-280.jpg)
![[Advertisement]](https://ipwatchdog.com/wp-content/uploads/2021/12/Ad-4-The-Invent-Patent-System™.png)







Join the Discussion
2 comments so far.
Anon
December 9, 2021 10:24 amNot sure who was counsel for Everalbum (or if the internal circumstances were in the throes of a death spiral), but I would think that the FTC order to destroy any work product could have been challenged as an overbroad and out of proportion (read that as the government no-no of arbitrary and capricious) ‘remedy,’ seeing as the technical process ‘scrubs’ any actual individual ITEM.
To play the ‘human parallel,’ people cannot be made to ‘unlearn’ something.